|
Author
|
Topic: Insurance Fraud
|
Buster
Member
|
 posted 11-27-2009 11:59 AM
posted 11-27-2009 11:59 AM
This is a first for me. The insurance company thinks that a case is fishy and our Insurance Fraud Unit gets involved. A tenant moves out and reportedly removes $10,000 of the tenants items including several antique vases and similar type heirlooms from the house. The roommate that reported the theft to the police is a 50 year old male who is a drinker (unknown about drugs).The local Detective said he interviewed well. I didn't talk to the detective directly. The owner of the house is the mother of the 50 year old victim. She put the claim in to the insurance company. In our point of view this would be the suspect. She put the claim in. The person accused of stealing the ten grand declined to be tested. I would have liked to test him first. I didn't talk to him --our insurance detective did. He said something like "I didnt take his stuff, I was already interviewed about this by the police and I'm not doing anything else for you guys or that asshole that accused me." I guess the possibilities are (1) He took all of the stuff (2) He took some of the stuff and mom over did the claim (3)he didnt take the stuff and the 50 year old sold the stuff for drugs or booze and told Mom to file a claim (4) Mom and Son are in a conspiracy together to report the stuff missing. Mom and son agreed to a test and they want me to do them both Monday. I don't know Moms age, but if hes 50 she is most likely elderly. That will admittedly be a little weird for me. I am starting use the DLC test, but I am leaning towards a CQT for this with the following: Son: C: Did you ever lie to anyone in authority? Did you ever lie on your taxes? Did you ever steal from someone who trusted you? I would bracket these according to the technique which I use. R: Did you fabricate the report to the police? Did you fabricate the report to the police last month? Can you take me to these stolen items? I have been doing mostly sex crimes lately and I am having trouble with this test. Any inout would be appreciated.
[This message has been edited by Buster (edited 11-27-2009).] IP: Logged |
rnelson
Member
|
posted 11-27-2009 09:15 PM
Evidence connecting question at R3 (R10) starts to look like you are thinking about a Federal ZCT.DLCs sound like a Utah. There is an awful lot of published research data suggesting that a single issue ZCT type exam provides the highest level of diagnostic accuracy. That, and our recent experiments into the decision theoretic problems and signal detection problems associated with multi-facet investigation approaches have me convinced that a multi-facet attempt at diagnostic accuracy will never achieve what a single issue exam can do. A single issue three question zone type test would be a Utah, which is composed of three primary relevant questions. Also, some reviewers might not be impressed by, or approve of, the idea using a Federal ZCT (or other) with DLCs. There is a trend in the reported literature that the Utah ZCT may outperform other techniques. Top be fair, and thorough, the reported difference has never been subject to any t-test that I've seen, and the reported difference is slight enough (a few percentage points) that the difference is most likely noty statistically significant - and possible not something that would be noticed in the field. However, the Utah does so far seem to have better accuracy figures, and that begs a question. Why? The answer to this question exists somewhere in the subtle but possibly important differences between the Utah and Federal Zone techniques. First, keep in mind that the reported accuracy figures were based on data that was scores prior to 2006, which means the Federal exams were scored with the old score-anything-that-moves federal method. The 2006 Fed PDD handbook describes a modern 12-features TDA methods that approximates the Utah and ASTM methods. To the degree that the difference in accuracy between the Federal and Utah ZCT exams was driven by scoring differences, the difference today may be less than we think. There are other differences, such as question rotation, use of neutral Qs, sympotmatics, and the evidence-connecting R10 But we can only hypothesize and expertize about the possible effect of these differences - which is a question that could quite easily be answered by a research study if we really wanted to know the answer) - so keep in mind that expert opinions are just hypothesis to be addressed with research (and keep in mind that most hypotheses end up discarded to the scrap heap after study). If you want a sure-footed approach, that stays within the presently established realm of what we think we know - I'd suggest using either a Federal ZCT - they way they say to use it - or a Utah ZCT. Or you can pimp-out your own hybrid type technique with all the poly-bling you like. Maybe something like a Federal Utah Comparison Test (try the acronym on that). .02 r

------------------
"Gentlemen, you can't fight in here. This is the war room."
--(Stanley Kubrick/Peter Sellers - Dr. Strangelove, 1964)
IP: Logged |
Bob
Member
|
posted 11-28-2009 02:00 AM
Buster,
First, let me see if I have the story right. An elderly woman owns a house, which she ‘leases/rents’ to two 50 year-old men (one of which is her son). Her ‘alcoholic son’ comes home one day, and his roommate had moved out and- reportedly with $10,000 in property (cash ?). Her ‘alcoholic son’ then contacts the police and files a complaint of theft against his ex-roommate. The mother, however, carries the insurance policy and files a claim listing the missing property as being stolen. The ex-roommate was later interviewed by the police and declines a polygraph test (because ‘he isn’t gonna do anything for his asshole ex-best friend). In addition to your listed possibilities is another: (5) the ‘alcoholic son’ hid the property- just to get his ex-roommate ‘arrested and jailed’ (as in revenge for some perceived wrong- particularly if they happened to be gay) and ‘Mom’ doesn’t know anything about it and erroneously files a claim. (Ok, I admit it, I’ve been talking with sex offenders way t-o-o-o- long) As Ray already suggested the specific issue test- either Utah Zone or Federal Zone would be the best format. Other potential CQ forms: Prefix a Time or Frame of reference plus, Did you ever lie on (or falsify) an official document to gain something for your benefit? Did you ever lie on (or falsify) any credit application form for financial gain ? Did you ever blame someone else for something you did just to get even? (or to protect yourself for any reason ?) Other potential RQ forms:
Are you the person who took any part of that missing property from your house? Are you the person who took any part of that missing property from your house which is insured by XYZ company ? Did you make a false police report to cover-up what became of that missing property from your house ? (I chose not to use words like steal, stole, or stolen in the RQs- but rather the softer form of ‘took and missing’ just in case the ‘alcoholic son’ came to viewpoint his mothers property somehow belonged to him- and how can you steal from yourself) Just some late night thoughts.
Bob IP: Logged |
Buster
Member
|
posted 11-28-2009 08:39 AM
Great input and science men. Nelson, I keep it pretty standard. If I do a CQT I use Nate Gordon's method, which is basically a "Backster You Phase". Bracketed Control
Relevant
Unbracketed Control
Relevant
Bracketed Control
Relevant Then, you rotate the relevants for three charts. That is what I was trained in and thats what I am comfortable with. If I do a DLC, I use a Utah. We did learn Utah in the academy, but I mostly learned that technique from reading about it and Ben trained me in that over the phone. The only way I determine which technique to use now is--if they know and research polygraph I use the DLC since I don't think its on the Anti site. Bob: You have the facts right. I don't know for sure if sonny boy was paying rent or not. I will examine your questions too. The part I was really having problems with is question selection. Have you guys ever tested anyone in their 70's and above? Do you have problems getting reactions or with cuff pain? Nelson: Back to the last question. Nate taught us for a single issue to ask: Did you do it?
Re: Did you do it?
Are you telling the truth about it? I have been toying with that third question a little. I know the old Reid started that "evidence connecting" as the third question. You don't like that in a single issue? [This message has been edited by Buster (edited 11-28-2009).] IP: Logged |
Bill2E
Member
|
posted 11-28-2009 11:18 AM
A very old school thought here, why not do a Backster SKY first, if you get reactions to relevants then do the single issue. Questions would be in this format So you suspect anyone of taking even one of those items? Do you know for sure who took even one of these items? Did you yourself take even one of those items? Did you plan with anyone to taken even one of those items? Your controls would be either theft related or lie related. IP: Logged |
rnelson
Member
|
posted 11-28-2009 08:29 PM
Bob:
quote:
Other potential CQ forms: Prefix a Time or Frame of reference plus,
Did you ever lie on (or falsify) an official document to gain something for your benefit?
Did you ever lie on (or falsify) any credit application form for financial gain ?
Did you ever blame someone else for something you did just to get even? (or to protect yourself for any reason ?)
A couple of these look rather narrowly focused to me – as if they attempt to describe a single behavioral concern in a CQ which should probably refer to a broad category of problem behavior (esp. when there are no time bars). quote:
Are you the person who took any part of that missing property from your house?
Are you the person who took any part of that missing property from your house which is insured by XYZ company ?
Did you make a false police report to cover-up what became of that missing property from your house ?
(I chose not to use words like steal, stole, or stolen in the RQs- but rather the softer form of ‘took and missing’ just in case the ‘alcoholic son’ came to viewpoint his mothers property somehow belonged to him- and how can you steal from yourself)
Just some late night th
“are you the person...” always strikes me as odd. Who talks like this? Do investigators approach suspects this way – if so, it sounds rather weak. If polygraph measures response to a stimulus, it seems to me that we we have the greatest degree of confidence in a passed or failed test if we stimulate the issue directly. If we want to observe, measure, and calculate the statistical significance of an examinee's response to a stimulus, then it makes no sense (scientifically) to simultaneously attempt to adjust or manipulate the intensity of the stimulus or the way the examinee will react. Just present the dad-gum stimlus, then observe, measure and calculate the reaction – without all the amature psychologizing. False police reporting seems like a good target to me. Buster:
quote:
Bracketed Control
Relevant
Unbracketed Control
Relevant
Bracketed Control
Relevant
By “bracketed” I think you are referring to what most of us call a time-bar. Is this the language Nate is teaching. If so, it's helpful to know that. Bear in mind that the research on time-bars is wholly unconvincing. They appear not to work as expected. There appears to be some face-validity to the idea of time-bars. However, fancy ideas like this are really just hypothesis that deserve to be investigated and answered by research. The joke on us scientists and experts - and there are many jokes on us – is that most of our fancy ideas, hypothesis, and expert opinions fall apart under research. We then throw them away and search for better fancy ideas that do stand up to empirical scrutiny and data. When we refuse to discard fancy ideas that don't work, simply because they are ours and we like them, then we cease to behave like scientists and we would be guilty of of the accusations of pseudoscience that our detractors want to point at us. So, polygraph professionals need to learn to be very careful about experts who willingly engage in the practice of “expertizing” - that is, thinking that our expert opinion is a sufficient substitute for data, and thinking that it is somehow OK to use our expert opinion to fill in the gaps in our knowledge-base that is supported by data. Here is another joke on us experts: expert opinions are opinions that are based on data. When an opinion is not based on data, when an opinion is based on one's expertise, years of experience, or anecdotal experience (which is all just unstudied data), then it is NOT an expert opinion – it is a personal opinion coming from an expert. Most real experts and scientists consider this a reckless, irresponsible and narcissistic thing to do – because they know that most expert opinions (which are just hypothesis that are still waiting to be studied) are disproved and discarded through scientific experiments. To scientists, expert opinions are things to be very careful with. I am not as familiar with the IZCT, but it seems loaded with fancy ideas like bracketed and unbracked CQs, and flipping the sequence of the red and green questions on the last chart. I would like to see some data that tells us what actually happens to the sensitivity and specificity levels when that is done or not done. It would be an easy experiment to complete do a 2 x 2 experiment, using maybe a chi-square or ANOVA, if someone had access to things like a polygraph lab, examiners, examinees and mock or real crimes to solve. It would be great if one of the polygraph schools could do some research on this. I think I've heard Nate express his concerns about the use of an evidence connecting question in the last spot, and whether this disrupts the formulation of a true single-issue test. Again, this is a fancy idea that deserves to be treated like a research hypothesis. A look at the available literature, using the Federal ZCT exams in the 2002 DoDPI archive suggests that it may be a less important concern than we have thought. The Federal ZCT exams seem rather consistently, in a number of studies, to provide the highest level of decision accuracy when they are scored as single issue exams – regardless of the evidence connecting R10. We are also reminded about the accuracy rates of the Utah Zone – with three primary RQs – that seem to have consistently provided a slight advantage. Again, no-one has yet taken the time to calculate the significance of the slight effect of the Utah approach. If we are going to advance the state of polygraph science to the point where we begin to experience better acceptance among our scientific peers and the courts, then we have to agree to put aside all egos and all personality contests and just follow the data. I do not suggest a form of cafeteria style polygraph where we pick and choose what we like and don't like. That was fine 40 years ago when we had nothing but our own creative genius to start with. But we have a lot of data now. As for old-school things like SKY. But, I think we have to start insisting on evidence, and access to the data, to support continued use of these things. The decision theoretic and inferential/statistical complications associated with multi-facet investigative approaches impose a reality that these approaches will likely never outperform a good strong single issue exam – in terms of sensitivity to deception, specificity to truthfulness and inconclusive rates. I would challenge anyone to find and show us the data on this. Our recent experiments on this, using Monte-Carlo statistical methods has me convinced. It seemed like a good idea at the time, but it is another one of those fancy-ideas... Old-school is cool, for sure, but in a museum kind of way. What we are finding is that Cleve Backster was absolutely right about some things – like the value of a well focused single issue test, and some other core ideas. To paraphrase Lou Rovner's question for me a couple years ago: how does one justify using anything other than a Utah ZCT when you want an argument for the most accurate test possible? This is a great question. My answer is that you cannot justify it. To be fair, I do not believe that the observed difference in effect is statistically significant between the Utah ZCT and the Federal ZCT – esp using the current 12 feature Federal scoring method (that's just my personal opinion in the absence of data). Accuracy estimates of the IZCT are derived using the ASIT or Horizontal Scoring method – which is really just a nonparametric rank-order approach, using ideosyncratic features that have never been studies or shown to outperform the 12 features that are more or less common to Utah, ASTM, and the current Federal method – which are based on multiple studies conducted by different (competing) groups of researchers over a period of more than 20 years. So, if you use and IZCT with ASTM, Utah or Fed/12 scoring then you probably don't know how accurate it is – because of the flipped red/green sequence in chart 3 (but the expert opinion on the effect of this would be greater sensitivity to deception at a cost of increased false-positive errors). We do know that a Utah ZCT had rather balanced sensitivity and specificity, and we also know that a Federal ZCT scored with 2-stage evidentiary rules can also have good balanced sensitivity to deception and specificity to truthfulness. I tested a 69 year old Anesthesiolgist a short time ago. 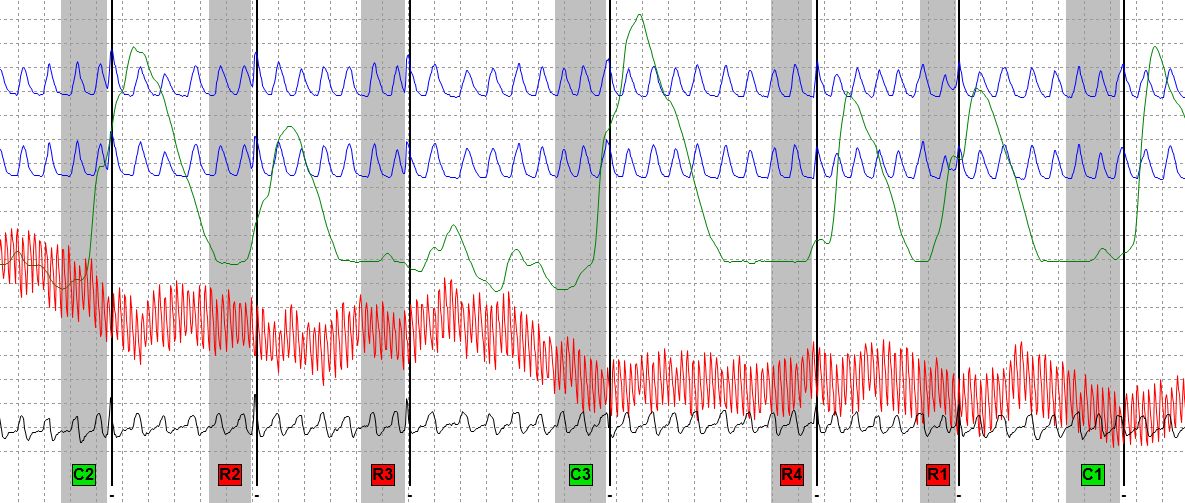
I am beginning to think general health and physical condition is more important than chronological age.
.02
r 
------------------
"Gentlemen, you can't fight in here. This is the war room."
--(Stanley Kubrick/Peter Sellers - Dr. Strangelove, 1964)
IP: Logged |
Bob
Member
|
posted 11-29-2009 12:29 AM
Good evening Ray and Buster- Nice chart of the Anesthesiolgist, wish I would see that clean of chart more often. I'm with you it's their general health and not chronological age. Only older people, I find, are a little more figity in the chair. You commented Ray, quote:
“are you the person...” always strikes me as odd. Who talks like this? Do investigators approach suspects this way – if so, it sounds rather weak.
No major rebuttal from me, it's not one of my favorite lines either, but I was trying to offer a different approach to Buster. Did you do it? Did you do it huh? is more direct, and how a police investigator should take a stance for behavioral cues- and therefore is good for the examiner too. However, I would suggest the 'intensity' of the question, may also be related to how the question is pre-tested as well. Do we not 'intensify' the control questions when we present them? quote:
False police reporting seems like a good target to me.
I've seen it used and I've used it myself as a relevant, but I was never a big fan of the 'falsify' word in a relevant question though. Back in the day when I did do investigative work, we had a common joke in our office that- we first had to investigate the police report before the crime. Meaning victims of burglary frequently reported things stolen when in fact they misplaced/lost an item being listed, or they figured adding their previously broken Tv to the list to get get a new one, was justified with all the years they paid premiums to the insurance company, BUT the main crime event (and stolen property)took place. Furthermore, when the complainant had a suspect in mind, it was not uncommon for them to embellish their reasoning for their suspicions. It also seemed the police officer taking the report from the complainant often added things, that I might say, was not totally accurate either. Bob IP: Logged |
Buster
Member
|
posted 11-29-2009 09:28 AM
Points well taken men.2 Questions: (1) What do you use as that third question in a single issue test then? (2) In your opinion (with all things being equal and we do not suspect countermeasures) do you now prefer CQT or DLC? Edit: I don't want to be a pain in the ass, but my Matte book and my polygraph laptop are at work, can you paste a single issue Utah into here (either blank, dlc, or cqt). Isn't there an issue with any of us using techniques that we weren't officially trained in?
[This message has been edited by Buster (edited 11-29-2009).] IP: Logged |
sackett
Moderator
|
posted 11-29-2009 01:51 PM
Buster,my only input is K.I.S.S. Use the technique you're trained in. And remember, fraud is simply theft via a lie. You're testing the son of the owner who is the roommate and knows if he or the roommate took the property. Of course, there is also the possibility that the owner is perpetuating the fraud with or without the son's knowledge. You may want to look at the act (of removal) rather than the intent, i.e. did you take any of that (reported stolen) property out of that house? Or, did anyone tell you they took any of that property from that house? This way you're applying his knowledge to the removal of property (since it didn't grow legs and walk out) rather than the so called "theft" or "lie." If you ask him if he stole it, and in fact his mother asked him to bring it over, he's gunna pass. If you asked about his lying on the report, when in fact his mother made the report (as owner) and he only removed the property from the house, he's gunna pass. We can always make this process more difficult to understand, but it boils down to knowledge and actions. Think outside "the box." And remember, there's more than one way to skin a mule... My $.02
Jim
[This message has been edited by sackett (edited 11-29-2009).] IP: Logged |
Barry C
Member
|
posted 11-29-2009 08:25 PM
quote:
Again, no-one has yet taken the time to calculate the significance of the slight effect of the Utah approach.
I filled in for Don Krapohl a some point in the not-too-distant past, and I presented his "Validated Techniques" lecture. Before I did so I asked if he knew if there was any statistical difference between the Utah and Federal ZCT mean accuracies. Although he didn't publish the finding, there was no difference, he said. (Perhaps with more data a significant difference could be found, but as of this point, we can't say that is the case.) IP: Logged |
rnelson
Member
|
posted 11-30-2009 08:38 AM
Barry:I am corrected. Thanks. But it's not published. I guess Don would use the test of proportions for this, which is OK, but a little weak on statistical power. Weak, in this case, only means there is a slight increase in a Type 2 error. Type 2 are false negative errors in polygraph, but in research it means we failed to find a significant effect that does in fact exist. Again, this is only a possibility. The difference in accuracy for the Utah and Fed ZCTs is 1 percentage point (.9 and .89), while the difference in INCs is .12 and .16. A more powerful approach to the same analysis would be to bootstrap a t-test or ANOVA. Bootstraping uses the power of modern computers do do massive resampling iterations. That's why we call them brute-force methods. We could design double bootstraps with moderate or large samples ,that can sometimes find even tiny statistical effects if they are in fact significant. But the thins is that tiny effects like 1 percentage point, may or may not be noticeable or important in real life field situations. I say “may or may not” because finding even 1 additional percentage point of accuracy is very difficult when you have a test that is already hanging around 90 percent accurate. That's because we are really achieving is a 10 percent reduction of the error rate – because logic of science and statistical inference is sometimes inverse (we are evaluating the opposite of what we think), and sometimes side-ways or crablike in that we use Cat-in-the-hat logic to find something by finding out where it is not. Again, the Federal cases in Don's 2006 paper were most likely scored using the old score-anything-that-moves system. It is possible that the modern 12 Feature system could perform more like the Utah. Most likely, with differences this small, a different distribution of sampling distributions could just as easily give non-significant results showing the opposite profile – with the Federal ZCT on top, due to random chance sampling alone – because that what it tells us when something is not statistically significant. .02 r
------------------
"Gentlemen, you can't fight in here. This is the war room."
--(Stanley Kubrick/Peter Sellers - Dr. Strangelove, 1964)
IP: Logged |
rnelson
Member
|
posted 11-30-2009 09:08 AM
Buster:I emailed you some Utah templates but the email (address on this site) was rejected. Here is a link.
http://www.raymondnelson.us/other/Utah_ZCT_and_MGQT.zip quote:
Points well taken men.
2 Questions:
(1) What do you use as that third question in a single issue test then?
Excellent question. One that is best answered with data, not a personal opinion. A lot of examiners like the BiZone or You-Phase technique for single issue diagnostic testing. It is sensible and efficient. Uses 2 RQs bracketed by 3 Cqs, and is scored to the strong side for each component. Seems to some like a fair and balanced test. The big problem with the BiZone is that non-body seems to be able to name or point to any validity studies on it. But we all know it and like it anyway, because there are obvious good things about it. We studied the accuracy of the BiZone using Monte Carlo techniques (computer intensive statistical methods resampling and simulation models). This allows us to make head to head comparisons of the signal detection and decision theoretic problems using both the BiZone and ZCT. The results are interesting. The Monte Carlo experiment is a computer simulation of ZCT and BiZone exams, using simulated manual scores, and seed data from the 2002 DoDPI archive. We constructed two monte carlo spaces of 100 simulated exams each for both ZCT and BiZone techniques. We fixed the base-rate of deception at .5 and set the criterion status of each of the 100 simulated exam in the ZCT and BiZone monte-carlo spaces by selecting a 20 decimal random number between 0 and 1. If the number was greater than .5 the case was categorized as truthful, less than .05 and it was categorized as deceptive. At this point we have 2 monte-carlo spaces (samples) of 100 simulated ZCT exams and 100 BiZone exams. Observed measurements were calculated by randomly selecting the manual scores from one of the 7 human scorers used in Experiment 4 of the Nelson Krapoh & Hander 2008 Brute Force study of OSS-3 and humans, then randomly selecting one of the 100 ZCT exams in that study, and randomly selecting the scores from one of the 3 RQs. The same procedure was used to construct the monte-carlo space of 100 BiZone exams, with the exception that 2 RQs were selected from the 3 RQs in the seeding data. We then had the computer do all the lathering-rinsing-repeating of this for 10,000 iterations of the two monte carlo spaces of 100 exams. One real advantage of a monte carlo simulation like this is that it allows us to study the efficiency of the decision theoretic model for ZCT and BiZone exams as if everything else is equal (equal because it is randomized 10,000 x 100 times from the same seeding data). The results are very interesting, and tell us a lot about the BiZone and ZCT. <> in a bit. r
------------------
"Gentlemen, you can't fight in here. This is the war room."
--(Stanley Kubrick/Peter Sellers - Dr. Strangelove, 1964)
IP: Logged |
Mad Dog
Member
|
posted 11-30-2009 12:46 PM
All,
A wonderful discussion and opportunity to reflect on some "poly-lore". I have heard examiners state one must be "formally trained" in a technique before they use it without qualifying what that means. I learned the Utah Approach and scoring from Charles Honts and grew quite comfortable using it. We had several discussions over the phone and I read about it in Murray Kleiner's book. That includes the DLC aspects of the testing. So one could argue I am not "formally trained" as I did not learn this approach in basic polygraph school., and I would beg to differ with them. Also, I see we are getting caught up in the minutia of semantics. While I agree asking the correct "Did you...?" is very important, examinees "pass or fail" because they are truthful or untruthful about the issue under investigation, not because they are lying to the specific wording of the question. Lots of way to fail and only one way to pass. To infer that our magic words or the examinee's ability to rationalize or compartmentalize a test stimulus with a cognitive coolness, is probably an error we torment ourselves and criticize one another over. I am thoroughly convinced that test subjects respond to stimuli with cognition and emotion that is commensurate with the relative degree of salience the target holds. I bet Charlie Brown's teacher could read the RQs to them and do just as fine a job without worrying about special phases (Are you the person who....?, "catch all" questions "Did you participate in any way in ....?", etc.R1-Wah Wah, Wah Wah, falsely report Wah, Wah?
R2-Wah Wah Wah, Wah Wah, falsely report Wah?
R3-Wah,Wah Wah, falsely report Wah, Wah, Wah? The subject knows why they are there. They know what this is about. They bring their own sets of goals, standards and values along with or without any cognitive memory of the event. I seriously doubt they could rationalize their way around the target of the false reporting of this claim. .02 IP: Logged |
rnelson
Member
|
posted 11-30-2009 01:09 PM
Accuracy estimates:Polygraph accuracy is not a simple thing to describe. It would be convenient for non-technical persons to have a single numerical index that describes the accuracy of the test. However, science simply doesn't work that way. When we say “accuracy” we mean many different things. In the past polygraph examiners have engaged in silly sounding conversations about “accuracy with inconclusives” and “accuracy without inconclusives.” I say these are silly because they are of interest only to polygraph examiners, and polygraph opponents probably enjoy all the hemming and hawing and unscientific jabbering and babbling over this. The scientific questions are these: 1) sensitivity to deception, 2) specificity to truthfulness, and 3) error rate (false positive and false negative). Inconclusive rates are of secondary or tertiary interest to scientists, mainly because these affect the efficiency (not accuracy) and economic$ of the test (how cost effective the test really is). So, as inconvenient as it is, if we are serious about understanding the accuracy of the polygraph we may have to grow-up our dialog a little, and give up hope for a single numerical index to describe the various aspects of test efficiency that make up the accuracy of the polygraph test. When we speak of accuracy, we are really talking about the accuracy profile, or accuracy characteristics of the test. Another thing to keep in mind is that we will never know exactly how accurate the polygraph test is – in a definitive sense – any more than we will ever know the exact average height or weight of the population in the US. A definitive number would require testing every single person under every possible circumstance – and the number of people and circumstances are themselves continually changing. What we have are estimates of the average height and weight of persons in the US, and we can study the variability in those estimates to make ourselves smarter. That is the point, every measurement in science is an ESTIMATE – a probability statement. Quantum physicists now tell us that even the laws of newtonian physics which define many common engineering circumstances, are actually rules based on probabilities – as in “the chair I am sitting on will probably support my body-weight.” Enough trials (millions and billions maybe), and we might encounter the rare outlier probability event in which it doesn't. So, ever assumption is a probability, and every measurement is an estimate. We have known this for a while. When we talk about accuracy of an algorithm or decision model, we know that we build the model on one sample of data, and then test it on another – expecting to see some shrinkage due to measurement error, overfitting, and sampling bias. All samples are biased – meaning that they are slightly inaccurate representations of the population. If you sample the average weight of persons living in coastal areas of Florida or southern California, you might have a slightly different estimate than if you take a sample of persons from the American mid-west or southern states. A really good estimate will generalize from one sample to another. A sample that generalizes well is said to be “representative.” To get really good estimates, we try to take random samples, which include persons from every region, represented in proportions that approximate the proportions in the population. We know that when we do this our estimates will be less biased and more generalizable – that is, they will transfer better from one sample to another. But there is still bias and still some error. Marketing researchers are the undisputed kings of another type of sampling – matched and stratified sampling. In these methods they construct samples that are effectively representative (but still biased in some ways) by purposefully, not randomly, selecting cases that will deliberately and strategically approximate or represent the demographics of the population they wish to study. The point of all this is that measurements are estimates, and that estimates are biased because our samples are always biased. We will never change that. The good news is that our samples are never completely biased. Our samples are also representative, but never perfect. The real goal is to understand the degree to which our sample is representative or biased. That way we can make intelligent assumptions about the degree to which we think our results and inferences are accurate or generalizable – or so biased and flawed they are not generalizable or representative of anything other than they sample they are based on. The silly conversations which we should learn to out-grow are the “accuracy with inconclusives” and accuracy without inconclusives.” Polygraph examiners are generally more interested in accuracy without inconclusives - because it is more flattering to us. But it hides the real information from us. Instead, it will be much more informative for us to learn to discuss the dimensional characteristics that make up the accuracy profile of the polygraph test. Those dimensional characteristics include: Overall decision accuracy - correct decisions without inconclusives. However, this figure is someone limited in its usefulness because it is non-resistant to base-rates. Sensitivity to deception - proportion of deceptive cases that are correctly classified (like accuracy for deceptive cases with INCs counted as errors). Whether we like it or agree with it or not is beside the point. This figure is important, because it tells us the likelihood we will catch a deceptive person. Specificity to truthfulness – proportion of truthful cases that are correctly classified (again, like accuracy for truthful cases with INCs counted as errors). And again, whether we like it or not – this brutal estimate of the good, bad and ugly is highly informative because it tells us the likelihood that a truthful person will pass the polygraph. false-negative errors – the proportion of truthful persons that can be expected to fail. false-positive errors – the proportion of deceptive persons that can be expected to pass. positive predictive value – the ratio of true positives to all positives (true + false). false positive index - the probability that a failed test is an error (the inverse of the PPV) and negative predictive value – the ratio of true negatives to all negatives. Also the probability that a passed polygraph is correct. false negative index – the inverse of the NPV. Keep in mind that all of these figures are estimates. And also keep in mind that estimates have confidence intervals - usually expressed as the range in which we are 95% confident the actual values exists within. Those confidence intervals are driven by the sample size and sample variance. Confidence intervals allow us to make intelligent estimates of the validity of a test – with 95% certainty regarding a certain estimated range of accuracy (or whatever level of certainty we wish to calculate). The big problem is that a number of these dimensional characteristics of accuracy are non-resistant to differences in base-rates or incidence rates. They are, in effect weighted by the base-rates of deception and truthfulness. So, we will see a test produce different accuracy profiles under low, moderate or high base-rate conditions. One advantage of a Brute-Force computer based statistical analysis, using Monte Carlo simulation is that we could randomize the base rates and run an exhaustive number of simluations. We could then calculate the PPV and NPV across all possible base-rates, and average these for a single unweighted numerical estimate and confidence interval of polygraph test performance across any unknow/random base-rate conditions. Neat huh? <> more in a bit.
r
------------------
"Gentlemen, you can't fight in here. This is the war room."
--(Stanley Kubrick/Peter Sellers - Dr. Strangelove, 1964)
IP: Logged |
Ted Todd
Member
|
posted 11-30-2009 01:33 PM
RayThe link doesn't work. Can you email it to me? THX Ted IP: Logged |
Barry C
Member
|
posted 11-30-2009 02:34 PM
Okay, the INC tests are another story. We don't know for sure, but that probably has to do with the Utah system allowing two more charts if INC after three. Since the Federal system now allows for a fourth or fifth, there should be even less of an effect, if any. What the data seem to show is that doing so reduces INCs about 11% or so, with no increase in errors.IP: Logged |
rnelson
Member
|
posted 11-30-2009 03:03 PM
Ted,In all the excitement I made the link but neglected to actually upload the file. It should work now.
http://www.raymondnelson.us/other/Utah_ZCT_and_MGQT.zip I've emailed them also. r ------------------
"Gentlemen, you can't fight in here. This is the war room."
--(Stanley Kubrick/Peter Sellers - Dr. Strangelove, 1964)
IP: Logged |
rnelson
Member
|
posted 11-30-2009 04:07 PM
Here are the accuracy profiles for the ZCT and BiZone, using a Monte Carlo model based on seed data from 100 ZCT cases from the 2002 DACA confirmed case archive, which were manually scored by 7 humans, using an empiricaly based 3 position scoring method based only on scoring features and principles which are supported by evidence of their validity (basically rejecting every fancy idea that has not been demonstrated and proven with data). Cutscores were not set arbitrarily, but are statistically optimized to provide decision accuracy at p <= .05 for deceptive decisions and p <= .1 for truthful decisions. The idea here is to try to constrain the FP and FN error rates to tollerable levels. Decision policies were 2-stage (Senter rules).First: accuracy estimates and confidence intervals for single issue ZCT exams with 3 RQs. 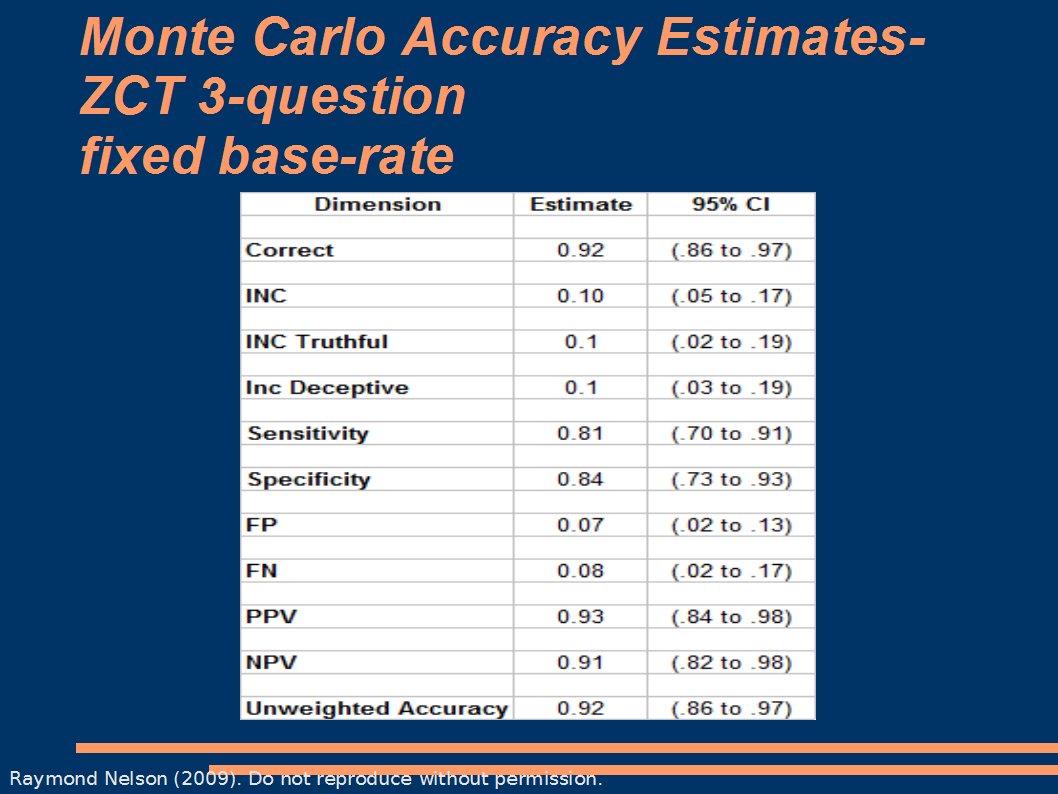
Notice that very nice balance of sensitivity and specificity - which is, I believe, just a little over what the NAS estimated. Confidence intervals are a form of validation experiement, because they allow us to estimate the range of error or bias, and therefore the range of maximum expected shrinkage under other conditions. Next: accuracy estimates and confidence intervals for single issue BiZone exams with 2RQs 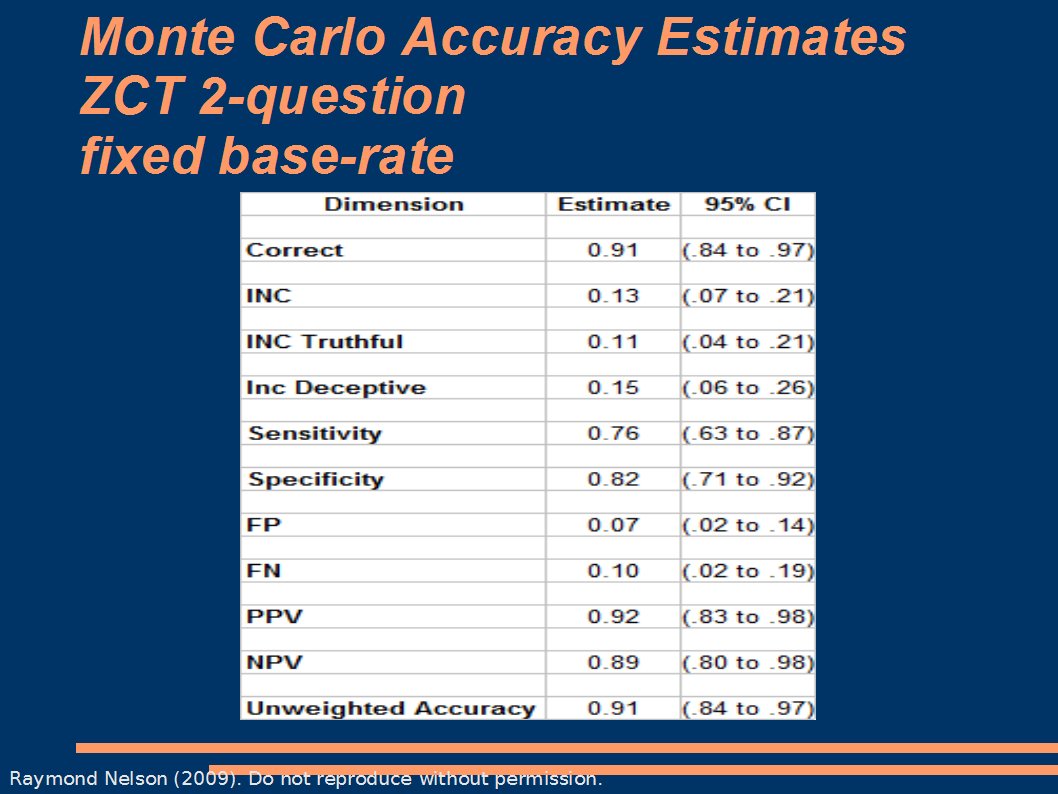
In these two charts, you'll notice that the unweighted estimate is identical to the decision accuracy. This is because the base-rate was fixed at .5 for these experiements. Randomizing the BR will cause some shrinkage in the estimate. That is what we want, because we know from monte carlo studies in other fields that monte carlo estimates will tend to be a little bit optimistic. We are not completely sure why this is, but it is probably related to the fact that monte-carlos, like all computer models, are basically dumb and can only process the data fed to them. What we really want is to study the influence of the unknown variance, but it is a tedious and ongoing process to feed unknowns to the monte carlo (because if we knew it enough to define it for the model it wouldn't unknown now would it). Anyway, monte carlo models can tend to become more sophisticated and more accurate over time, as we account for more and more degrees of variance. And finally: a bar chart with both 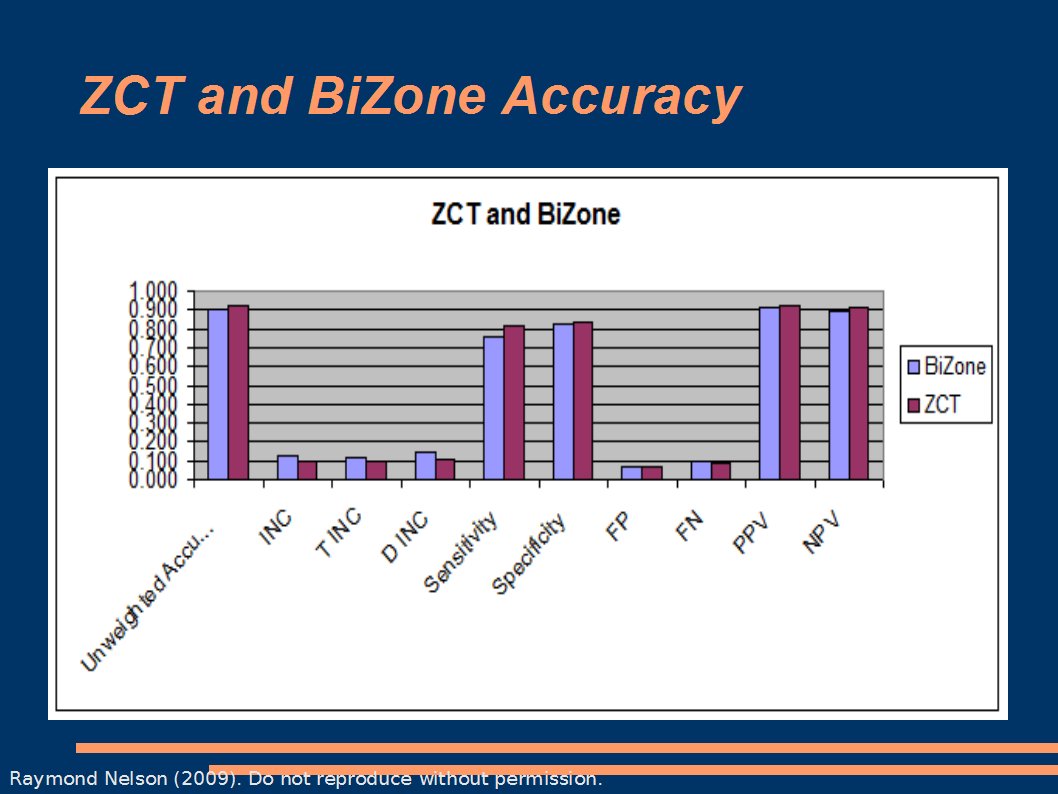
What these data seem to suggest is that, all else being equal, the decision theoretic, signal detection, and inferential statistical model of the 2-RQ BiZone may NOT outperform the 3-RQ ZCT. So why do we like the BiZone. First is is simple and elegant, and it's clear to us that it is supposed to be a single-issue exam (did you do it? / did you do it, huh?). We easily restrain the impulse to pimp the thing out with some silly evidence connecting or multi-facet nonsense. Therefore our experience with it has probably tended to be rather good. Look carefully at the graphics above and you'll see very little difference between the BiZone and ZCT, though the ZCT does seem to have a slight advantage. This is probably not statistically significant in most dimensions, but as they say - every little bit can help. The most important thing is this: Buster:
quote:
(1) What do you use as that third question in a single issue test then?
Answer: a third presentation of the single-issue stimulus, which should probably be logically identical and only semantically different. Think of it this way. Someone says there are apples in tree and its your job to investigate and test that concern by stimulating the issue (shaking the tree). Do you want to shake it 6 times (2 RQs x 3 charts) or 9 times (3 RQs x 3 charts). If there are apples in the tree, you have a better chance of observing them, as they react by falling, if you shake it 9 times. If there are no apples in the tree, and nothing to fall, you are more confident you don't have a type-2 error (in which there are in fact apples that have not fallen) if you shake it 9 times. To put it differently: more measurements = narrower variance. Narrower variance = more confidence in the meaning of the result. Another analogy: Someone says you have to stimulate a target by putting bullets onto it. Do you want 9 bullets or 6? Which will better guarantee an adequate job, in chaotic field settings in which not all bullets, pistols, environmental conditions, targets and shooters are created equally? To be sure, there is probably nothing really wrong with the BiZone. But how can we justify doing anything other than that which we know will give us the optimal results? Sorry for the long answer to why we need a 3rd RQ. r -------
next up:
quote:
(2) In your opinion (with all things being equal and we do not suspect countermeasures) do you now prefer CQT or DLC?
First: The point of all my ranting for the past 2 days is that my preference, or the preference of any other expert, is not what matters. And we should be very suspicious of any expert who thinks there preference does matter if it is not supported by data. Interestingly, Charles Honts has been working on studying this... Does anyone know if he ever joined the forum? .02
r
------------------
"Gentlemen, you can't fight in here. This is the war room."
--(Stanley Kubrick/Peter Sellers - Dr. Strangelove, 1964)
[This message has been edited by rnelson (edited 11-30-2009).] IP: Logged |
Buster
Member
|
posted 11-30-2009 07:10 PM
Men:Thanx, I will go read these in detail now. Nelson, Sorry I never updated my profile. I moved to the Prosecutor's Office. bhamilton@cmcpros.net IP: Logged |
Bill2E
Member
|
posted 11-30-2009 08:46 PM
As for old-school things like SKY. But, I think we have to start insisting on evidence, and access to the data, to support continued use of these things. The decision theoretic and inferential/statistical complications associated with multi-facet investigative approaches impose a reality that these approaches will likely never outperform a good strong single issue exam – in terms of sensitivity to deception, specificity to truthfulness and inconclusive rates. I would challenge anyone to find and show us the data on this. Our recent experiments on this, using Monte-Carlo statistical methods has me convinced. It seemed like a good idea at the time, but it is another one of those fancy-ideas... Old-school is cool, for sure, but in a museum kind of way. What we are finding is that Cleve Backster was absolutely right about some things – like the value of a well focused single issue test, and some other core ideas.Ray Why not do some research on the SKY formate as an investigative approach to see where we need to go with a BiZone? The SKY is not a stand alone test. If one is showing deception to one of the questions you then run a specific issue on that issue before concluding anything. I would like to see some research on this too. Old School is Old School, which does not make it invalid, it simply means it has worked in the past and no one has taken the time to do research. I am not a research scientist and would not attempt to represent myself as one. Would you be willing to take on that task? IP: Logged |
Barry C
Member
|
posted 12-01-2009 02:42 PM
quote:
it simply means it has worked in the past and no one has taken the time to do research
If nobody has taken the time to do the research, then we don't know if it worked. We might think it did, but that doesn't mean it really worked. If you remember correctly, the Xerox machine "worked" too. Why don't we still use it? Because... it doesn't work. As for SKY, which do you mean? There's a Backster SKY and a Federal SKY, which are very different. IP: Logged |
rnelson
Member
|
posted 12-01-2009 05:12 PM
Bill:I'm always happy to make myself googly-eyed (more googley-eyed) looking at data and numbers if'n you got 'em for the SKY. As a private examiner who does mainly PCSOT and some investigative polygraphs, I don't use SKY. Unless someone can convince me otherwise, the SKY is just a multi-facet approach to target selection and question formulation in the context of a known incident. The logic of if seems flawed in the context of a known allegation (in which the existence of an alleged incident is still suspect). Acromyms like S-K-Y are cute, but it is important not to allow their convenience to limit our intelligence. It is unlilely that there is something magical about those particular letters or the words they stand for. Therefore, unless it is proved otherwise, suspect-knowledge-you may be just as good or bad (valid or invalid) as any other set of multi-facet targets. Barry, can you tell us more about the exact procedural and empirical differences between Backster SKY and Federal SKY? I agree about the "it worked" response. A 1970 VW woks too. I could probably find one and drive it across the country today. But it might not make the best cross-country road -trip experience. Old VWs always leak a little, they have silly breaker-point ignition systems, and need valve adjustments every 3k miles to be happy. Then there are the head bolts that require periodic retorqueing, no AC systems, and the Zen-meditation approach to steep hills with a 1.6L air-cooled squirrel-cage fed by a leaky single-barrel 30mm Solex Carburetor. But they work, and those old-school VWs are kinda cool. My point is this: why should we choose a piece of polygraph technology in a different way than we choose other technology? We shouldn't. We should choose the best modern technology available. What very little research exists on multi-facet tests (Podlesney and Truselow, 1983, for example) reveals some not very impressive realities about multi-facet exams, and the entire multi-facet literature base right now is not sufficient - to me - to recommend it's use. To be useful it has to have some advantages. What are those advantages? It has been supposed that the formulation of different questions could point us to the correct assumptions about role-involvement in a known incident. This notion has not been supported by past studies. Sure, maybe they missed it, but the studies were, in fact, done by smart educated and scientific minded folks. We've done some recent monte-carlo experiments to calculate the accuracy profiles and confidence intervals for multi-facet investigation polygraphs such as our modern MGQTs (Air Force) that are consistent with the present state of our knowledge about valid polygraph testing principles. I can show the results if anyone is interested. .02 r
------------------
"Gentlemen, you can't fight in here. This is the war room."
--(Stanley Kubrick/Peter Sellers - Dr. Strangelove, 1964)
IP: Logged |
Barry C
Member
|
posted 12-01-2009 06:26 PM
Maybe Ray can talk again about incremental validity. I don't think the things that "worked" in the past had much of anything to do with polygraph. I think good investigators / interrogators / deceit sniffers caught people and credited polygraph. It's only when polygraph actually adds anything that it really can be considered to "work." We talk about "utility," but in the psychological literature (behavioral) that term refers to the subjective value a person assigns to something. When we talk of it, we seem to mean polygraph tells us a little something, but not enough to satisfy others (usually scientists). This is almost the same argument restated. Backsters SKY is the Suspicion Knowledge You test that is run as a standalone test. The Feds used to add three questions S-K-Y to the end of a ZCT (the three RQ version, which becomes a five RQ version). If memory serves me, they are the same questions in regard to the SKY abbreviation. S = CQ and K and Y = RQs. It is believed that a person would "suspect" someone, or at least react to that question (I guess). Just so this doesn't look like a hijack - I don't know how you'd use the SKY with these case factss. (Actually I've forgotten the issue. Maybe you could. I just don't want to look rude.) IP: Logged |
Mad Dog
Member
|
posted 12-01-2009 07:06 PM
Hey Bill2E,
My name is Mark Handler and I think we met at a seminar. I could not find an email address for you but wanted to run something by you that is tangential to the post. My email address is;
polygraphmark@gmail.comTake care man. IP: Logged |
Bill2E
Member
|
posted 12-01-2009 08:01 PM
We could argue all day about the Backster SKY and get now where with any argument. Matte called his the SKG. The DOD used the method also, only with different format. I was Backster trained, and the Backster SKY is not a stand alone test. If you react to a relevant question then a Backster A You Zone is conducted on that question. This is how it was taught in the school. IP: Logged |
Barry C
Member
|
posted 12-01-2009 08:25 PM
Bill,What I meant was that you run it by itself - not as part of a YOU-phase or standard ZCT. Ray wanted to know the difference between the Federal (DoD) and Backster, which is what I told him. The feds tacked it on to the end, and Backster ran it as a standalone test. Sure, he broke out the issue if necessary (sounds like successive hurdles, huh?), but if the guy confessed first, there was no You-phase. It "stood alone" in that it gave him information (which is what polygraph should do) to narrow his focus with his better test. (Backster was a brilliant man who was ahead of his time. Without a scientific background he figured a lot out almost intuitively. Imagine what he could do if he had another 50 years with us!) The issue isn't Backster vs feds vs Matte vs whoever you want to place here. It's simply what works and what works best. What you see in Ray's data is what scientists have told us for some time: generally speaking, more (good) data means more accurate results. Thus, you can expect Backster's three RQ version of the ZCT to be a little better than the You-phase (with 2 RQs), and you can expect that more charts (more data) will help with that end too. (See Ray's apple tree example.) IP: Logged |
rnelson
Member
|
posted 12-01-2009 08:52 PM
Incremental validity is the scientific concept that most closely resembles what we seem to be attempting to mean when we say "utility." At least I hope this is the case. The NAS used the term "utility" in a perjorative manner - as in they didn't want to believe the test is based on good science but conceded that it may at times get more information. Polygraph examiners usually seem to use the term "Utility" as a fox-hole to hide in when they are afraid of dealing with actual validity issues - as if we are afraid we won't be able to defend the science or answer questions about validity. It's not impressive.Incremental validity is the idea that profresssional decision will tend to be more accurate - more valid - when we use information, even if the information was obtained from an imperfect test. To provide incremental validity, we simply need to ensure that the information we gather matters - that we spend our time gather information that does actually matter. This also requires that we not waste effort and resources gathering information that satisfies only or sensibilities or values and beliefs. We have to dredge the things that contribute and don't waste effort dredging additional information that is not actually additive to the decision process. So, the question we must ask about our questions and the information we pursue is: how does this matter to the referring agent? The best answer would be that the info matters because of an actuarially defined risk prediction model. The worst answer is based only on a system of values, beliefs or attitudes. So, for a SKY test or other multi-facet approach to add incremental validity to the decision-support value of the polygraph it would have to perform better than a single issue test in some important way. Better, in terms of polygraph testing, means several possible things: The historic assumption, which has not proved itself is that multi-facet questions will somehow pinpoint the examinees behavioral role involvement. This assumption is steeped in other assumptions about fear-of-detection as the primary underlying force driving the polygraph. Which is why we need to un-lock our intelligence and grow beyond this. Fear-of-detection cannot explain things like DLCs and why the polygraph works with psychopaths. So we know it is reductionistic to the point of being inaccurate. To work, we'd have to prove that our pneumo tubes and other components can differentiate fear from other strong emotions. Then we'd have to prove that our pneumo tubes could also differentiate that reason for that fear. This is silly, and neglects the important and well established psychological domains of cognition and behavioral conditioning - placing all our professional eggs in the emotion basket. It is likely that strong emotions do play an important role in polygraph stimulus-response models. It is also likely that cognition and behavioral conditioning also play an important role. The combination of these (integrative psychology) can explain the variety of observed polygraph phenomena. Emotion, cognition and behavioral conditioning together can explain why PLCS and DLCs work, and why the polygraph works with psychopaths (who are known to have low levels of fear conditioning). Mark:
quote:
R1-Wah Wah, Wah Wah, falsely report Wah, Wah?
R2-Wah Wah Wah, Wah Wah, falsely report Wah?
R3-Wah,Wah Wah, falsely report Wah, Wah, Wah?
Mark's point is that we are silly to assume that linguistic precision will make the polygraph accurate. Let's facet, some criminals are just kind of dumb. They are not that smart, and lack logic and precision in their thinking, hearing and processing of information – just as they lack precision in behavior and judgement. Yet the polygraph works. Why? Because the examinee reacts to the stimulus, either due to some strong emotion (like fear of detection), or cognition (like memory and recognition of the crime details), or behavioral conditioning (having been their and eaten whatever kind of meat powder is described in the test stimulus question). We know from our own published studies that the polygraph does not effectively differentiate crime role involvment. The polygraph is good at detecting when someone is lying or withholding information, but not always so good at detecting when exact behavioral issue the subject is lying about. This is why, when you read the literature on the TES, you'll see that it is said that people pass or fail the test (as a whole) not the individual questions. Of course, all of this presents a bit of a complexity for those of us who have been encouraged to assume in linguistic and target precision within the polygraph. What happens during a polygraph is simple. We present relevant and comparison stimulus and observe/measure the subjects reaction. We present each stimulus several times to obtain a most stable estimate of the subject's reaction. We infer that the largest general reactions will be caused by the most salient stimulus, and that the stimulus is more salient because the subject is deceptive – lying or withholding information. We are right about 90% of the time when we do this carefully, according to valid principles. 90% accuracy is darn good psychology, darn good in medicine, and darn good in social work with criminals and dangerous people. So, what is possibly better about a multi-facet test, compared to a single issue exam? Better, in testing, would have to mean one or more of the following: - better sensitivity to deception,
- better specificity to truthfulness
- fewer INCs
- fewer FP errors
- fewer FN errors
- better PPV (lower FPI)
- better NPV (lower FNI)
- better unweighted accuracy
They ideal way to study this would be to find a set of conditions in which we could assume all conditions are equal except the decision model itself – then compare a multi-facet model to a single issue model using the same data. We'd have to have a sample of data to throw at the two models, and ideally we'd have lots of sample to do that with. We'd also need several humans to manually score the data for us, so that we can average across scoring abilities. Or we could use an automated scoring model for a completely objective solution. We would do it a lot of times and we'd expect to see some degree of variability. If we had access to the data to do this, and if we could do it enough times we could begin to answer our questions about the possible advantages of multi-facet investigation models. Hey, guess what. We have an archive of confirmed cases, and several powerful computers. We even have manual scores from several humans – and they are nice inexperienced humans so there is no risk of contamination or influence by expertise (uncontrolled variable). And we have lots of fancy software to build things like Monte Carlo experiments to do exactly this. Guess what else. We've now done it. Here is a table of Monte-Carlo accuracy profiles for multi-facet investive polygraph with 2, 3, and 4 RQs. 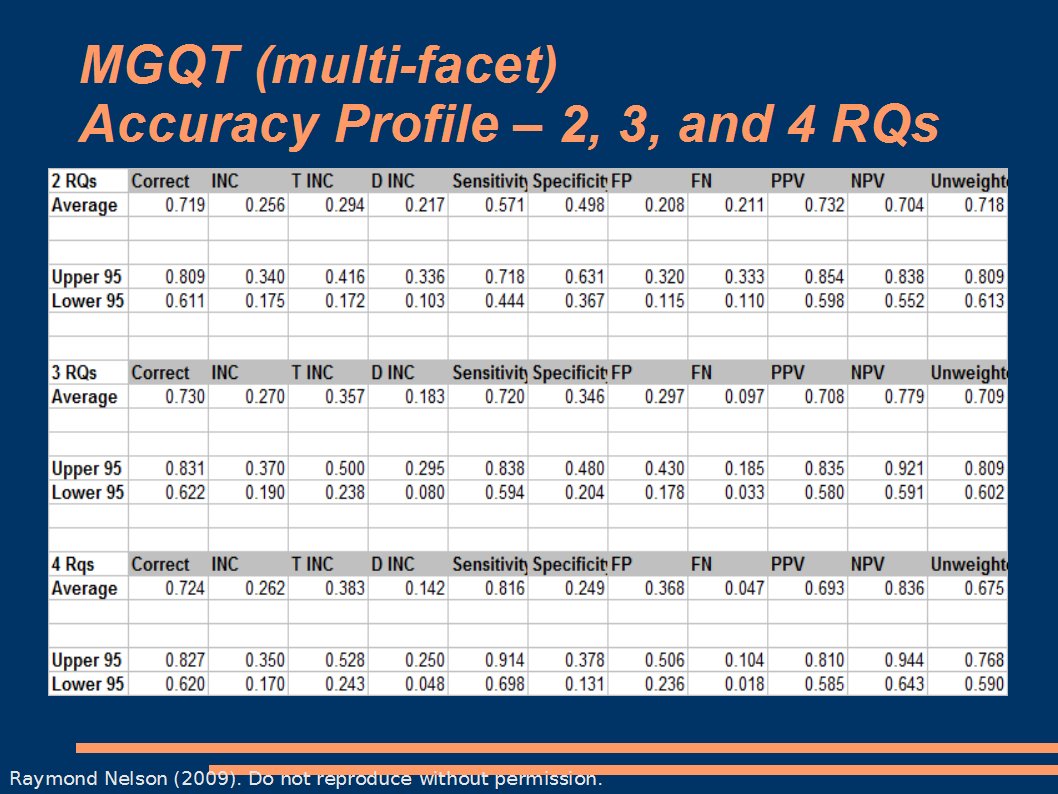
The table is boggling, so here is an easier view. 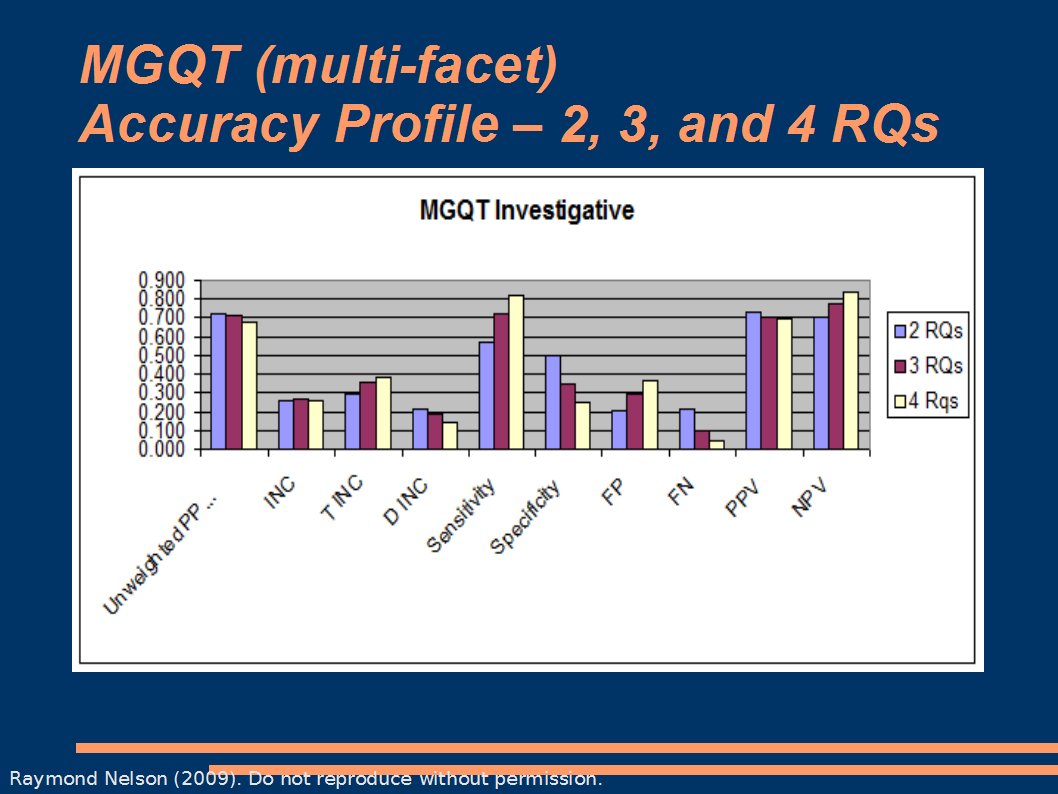
The obvious thing is that more questions does increase the senstivity to deception, but at a cost of decreased specificity (more opportunity for errors with more questions in a spot scoring model). Of course, false negatives do go down. Here is the Monte-Carlo estimate of accuracy for ZCT exams. (same as earlier post)
And a chart comparing them. 
Seems fairly obvious to me by now. All else being equal – because we randomized it 10,000 X 100 times from the same seed data. The basic mathematical decision model of a multi-facet test does not appear to offer ANY advantage over a single issue test – and there seem to be some disadvantages. Perhaps there is something else to consider. Someone would have to articulate exactly what that is. Of course, if anyone knows how to build a multi-facet decision model that is more accurate than this, then I'm open to suggestions. For now, I think the data are telling us that a single issue ZCT exam is probably the best approach for diagnostic and investigative work. What this means in terms of incremental validity and the investigation of a suspected fraud, is that if we want to use the polygraph to help investigators make better decisions, we would may do a better job sticking to good single-issue testing principles. .02 r
------------------
"Gentlemen, you can't fight in here. This is the war room."
--(Stanley Kubrick/Peter Sellers - Dr. Strangelove, 1964)
[This message has been edited by rnelson (edited 12-01-2009).] IP: Logged |
Ted Todd
Member
|
posted 12-01-2009 09:39 PM
Buster,Just do the damn test and let us all know how it came out! All my love, Ted IP: Logged |
Buster
Member
|
posted 12-01-2009 09:39 PM
This is good stuff, so hijack whenever need be. Mom was actually 77 and I had a problem with GSR that I could not solve. I ran the test anyway---even though I was not happy with our favorite component being missing. I ran a Utah DLC single issue test. Her cardio was very stable, so stable that there was no discernable difference between relevants and comparisons. She did not claim any major health problems for someone her age. I did have problems getting a good fit with the resp cables, but got them pretty good. I had to no call her. I had him (son)to the office later in the day and have him a Utah CQT on an old machine with (Windows 98) that my Lt has not used since 2001. He passed. I used the fake report route since he reported the items missing to the police and filled out a form putting a list of all of the missing items. Off on a tangent, it appears there is a hardware problem with the gsr. I called Lafayette and my local rep for help. It worked one day and not the next--pretty strange. Edit: Let ,me know if anyone wants to see a sample chart of a 77 year old on the box w/o GSR. The suspect (roommate) told the local detective that he would take the test until he was scheduled to take it then he backed out. We try not to look into this too much, but he doesn't look great for him. I am fairly confident that Mom is telling the truth from our conversation. Great conversation and great tips. [This message has been edited by Buster (edited 12-01-2009).] [This message has been edited by Buster (edited 12-01-2009).] IP: Logged |
rnelson
Member
|
posted 12-02-2009 10:30 AM
After all this,send the charts. I can post 'em here if you want. r ------------------
"Gentlemen, you can't fight in here. This is the war room."
--(Stanley Kubrick/Peter Sellers - Dr. Strangelove, 1964)
IP: Logged |
Bill2E
Member
|
posted 12-02-2009 07:27 PM
Great discussion and many points to ponder. I do agree that a single issue test has higher accuracy and validity than any multiple issue test. I'm working on getting the DLC down. Will in all probability attend the NM seminar in May to learn more. I'm not too old to change or learn. These discussions do cause me to study more and I learn from all of them. I will not run a DLC until I receive some formal training. Just the way I operate. And thanks Ray for all the statistical data, it will take me days to wade through all of the stats. (and I may understand some of them)IP: Logged |
stat
Member
|
posted 12-02-2009 08:56 PM
In my experience, Insurance companies think all claims are "fishy" and will use the tax payer for free investigatons at every opportunity. It's also a helluva way to delay a claim for 190 days (varies from state to sate) by crying "fishy." Time equals money, and late reimbursements makes up a big part of Insurance Co's earnings----they hold on to their monies which are actually investments that (most of you know this) earn interest while NOT going to mom and her $10k claim. Theft/fraud intero-questions and themes can be big fun, as they are best served deceptively mild, sweet, and smart. I wonder what your 50yr old's behavior cues would have been if he suspected that you were in very recent communication with the missing roommate--such as during a break---just a gnawing suspicion that is. There are interesting and ethical ways to feel out such things, even if he is in cahoots with the old roomy---it would have been interesting.
It was probably a heckufa lot tougher than should have been with instrument problems, eh? It's like trying to play chess in the rain. It makes great sense why many examiners (who can) spare no money when it comes to instrument, office, and appurtenances. It's very comforting when the gear has your rear. [This message has been edited by stat (edited 12-03-2009).] IP: Logged |
Poly761
Member
|
posted 12-03-2009 02:28 AM
What have I missed when you stated you had a GSR problem and "I ran the test anyway." What did I not read accurately? It appears to me you conducted the test without a GSR. END..... IP: Logged |
J.B. McCloughan
Administrator
|
posted 12-03-2009 11:45 PM
I just wanted to comment on a couple points of this discussion, even if it is late.Firstly, I believe the questions posed in the test are partially the stimulus provided to cause the response, this could go on but I will leave it that simple. I like asking simple, to the point questions that cover an action, “did you do it?” However, I also like to ask questions such as, “Are you the person who did this?” or “Is X telling the truth about you doing this?” The first alternative goes directly to the heart of whether or not the subject is withholding their involvement in the action. The second alternative I use because sometimes the subject may not perceive the action as significant but does hold significant the truth of the others statements, as they don't want you to find out they are true. As long as the questions revolve around the same action, we are covering the same thing but allowing for the possibility that more than one thing associated with that action might be significant and memorable. I won't bore you with an further on this. Lastly, I wanted to make simply clear the difference between validity and reliability, as there has been some discussion in this thread regarding it. Cook and Campbell (1979) say the following regarding validity, "...best available approximation to the truth or falsity of a given inference, proposition or conclusion." Validity therefore, simply, is how certain we are that something is what we say it is. Reliability is simply how well we can repeat the results we get. So, repeat scoring of the same test is simply a test of reliability. I don't want to go into the aforementioned concepts too in-depth, unless necessary, as I think over complicating them makes them just that more confusing when they need not be. [This message has been edited by J.B. McCloughan (edited 12-03-2009).] IP: Logged | |


 Polygraph Place Bulletin Board
Polygraph Place Bulletin Board